A model that runs on your laptop today and nowhere else tomorrow is a liability, not an asset. The gap between “it worked when I trained it” and “it works in production, again, next quarter, on a colleague’s machine” is closed by two engineering practices borrowed from software: reproducibility (the same inputs and code produce the same outputs) and continuous integration / continuous delivery (CI/CD, the automatic building, testing, and shipping of changes).1 This chapter applies both to the specific shape of machine learning work in R.
If you have never set up a test suite or a build pipeline, do not worry: the ideas are simpler than the acronyms suggest, and you can adopt them one piece at a time. By the end of the chapter you will know how to pin an exact computing environment so results travel between machines, write a test that refuses to ship a model unless it clears a quality bar, run that test automatically on every change, and retrain on a schedule without a human having to remember. The single runnable example is the part that matters most: a small assertion that checks a model’s holdout metric and stops the build if it falls short.
Intuition
Reproducibility is about making the past repeatable; CI/CD is about making the future automatic. Together they let you trust that a model you cannot personally babysit is still behaving.
The pieces fit together as a chain. Reproducibility starts with pinning the exact package versions a project uses (renv) and organizing files so the pipeline is discoverable. Tests (testthat) state what “correct” means for data and models, including the threshold a model must clear. CI (GitHub Actions) runs those tests on every change so regressions are caught before merge. Automated retraining extends the same machinery to run on a schedule or when new data arrives. A model card records what was built and how it should be used. The runnable core of the chapter is a testthat-style assertion that validates a model meets a metric threshold on a holdout set, because that assertion is the gate everything else protects.
118.1 Where CI/CD and reproducibility fit in a modern ML workflow
A typical project moves through stages:
set up env -> structure project -> write code + tests -> commit -> CI runs tests
-> train -> evaluate vs threshold -> register model + card -> deploy -> monitor -> retrain
Reproducibility is a property that must hold at every arrow, not a step you do once. CI/CD is the automation that enforces it: instead of trusting a human to rerun the tests before merging, a machine reruns them and blocks the merge if they fail.
Key idea
Reproducibility is not a checkbox at the end of a project. It is an invariant that has to survive every transition in the diagram above, which is exactly why automating its enforcement pays off.
Three observations motivate the investment.
ML failures are often environmental, not logical. The same code gives different numbers because a dependency changed its default, a random seed was unset, or a BLAS library differs across machines. Pinning versions and seeds removes the most common source of “works on my machine.”
Models decay even when code does not. Data drifts, so a model that passed its threshold last month may fail it now. A retraining pipeline that re-runs the same evaluation gate catches decay automatically, complementing the dedicated drift surveillance covered in the model monitoring chapter (Chapter 117).
The evaluation gate is the contract. The single most useful piece of automation is a test that refuses to promote a model unless it beats a metric threshold on held-out data. Everything else (environment pinning, CI, scheduling) exists to make that gate trustworthy and to run it without a human in the loop.
In an AI/ML setting these practices also guard against a subtler problem: a change that improves average accuracy while quietly degrading a slice (a subgroup, a recent time window). Tests that assert per-slice thresholds, run in CI, turn that risk into a build failure instead of a production incident.
With the motivation in place, the rest of the chapter works through the chain one link at a time, starting with the formal target that everything else serves.
118.2 Reproducibility: the formal target
“Reproducible” sounds obvious until you try to pin down which things have to stay fixed. It helps, then, to state precisely what reproducibility asks for. Think of a training run as a machine with four dials; lock all four and the output should be the same every time. Let a training run be a function
\[
M = T(D, \theta, s, E),
\]
where \(D\) is the training data, \(\theta\) the hyperparameters and code, \(s\) the random seed, \(E\) the environment (R version, package versions, system libraries, hardware), and \(M\) the fitted model. A run is bitwise reproducible when fixing \((D, \theta, s, E)\) always yields the same \(M\). It is statistically reproducible when the resulting evaluation metric
is stable within a small tolerance \(\epsilon\) across runs, i.e. \(|\widehat{R}(M_1) - \widehat{R}(M_2)| \le \epsilon\).2
Each of the four dials is a source of irreproducibility if you leave it free. The following list names each one and the cheapest way to lock it down:
\(D\): pin the data with a hash or a versioned snapshot, so a silently mutated table is detected.
\(\theta\): version the code (git) and record hyperparameters alongside the artifact.
\(s\): set and record the seed. Many R model fits (random forests, boosting, cross-validation splits) are stochastic.
\(E\): pin package versions with renv. This is the argument most often ignored and most often responsible for drift, because package updates change defaults and numerical behavior.
The practical goal is usually statistical reproducibility, not bitwise: parallel reductions and floating-point nondeterminism make exact equality hard, but a stable metric within tolerance is enough to trust an evaluation gate.3
Key idea
The promotion gate is a hypothesis test in disguise. We promote \(M\) only if \(\widehat{R}(M)\) clears a threshold \(\tau\) on a holdout the model never saw. Everything else in this chapter exists to make that test trustworthy and to run it automatically.
118.3 Dependency pinning with renv
Of the four dials, the environment \(E\) is the one most people forget and the one that bites hardest, because a package update can silently change a default or a numerical routine without any change to your own code. renv (short for “R environment”) is the tool that locks it. It gives each project its own private library and records the exact version of every package in a lockfile (renv.lock). Restoring that lockfile on another machine reconstructs the same environment, which pins the \(E\) argument above.
When to use this
Reach for renv at the very start of any project whose results you might need to reproduce later, on another machine, or with a collaborator. It is the single highest-value reproducibility step for an R project, and it costs about three commands.
The workflow is small. Because renv writes to a project library and contacts package repositories, this chunk is eval=FALSE, but it is the idiomatic sequence a reader runs in a real project.
Show code
# install.packages("renv") # once, into the system library# 1. Initialize: creates a project-local library and an renv.lock snapshot.renv::init()# 2. Work as usual. Install/upgrade packages into the project library.install.packages("glmnet")install.packages("yardstick")# 3. Snapshot: write the current package versions into renv.lock.# Commit renv.lock (and the renv/ infrastructure) to git.renv::snapshot()# 4. On another machine / in CI: reconstruct the exact environment.renv::restore()# 5. Audit drift between the lockfile and what is actually installed.renv::status()
The lockfile is JSON and records, per package, the version and the repository it came from. A trimmed example:
Show code
# renv.lock (excerpt) -- this is data, not code; shown for shape only# {# "R": { "Version": "4.4.3" },# "Packages": {# "glmnet": {# "Package": "glmnet",# "Version": "4.1-8",# "Source": "Repository",# "Repository": "CRAN",# "Hash": "..."# }# }# }
Two rules make renv pay off. Commit renv.lock so the environment travels with the code, and run renv::restore() as the first step of every CI job so the build uses pinned versions rather than whatever CRAN ships that day.
Warning
Commit the lockfile, not the library. The actual package files live under renv/library/ and should be left out of git (they are large and machine-specific). The lockfile is the recipe; the library is the meal, and you only need to ship the recipe.
118.4 Project structure
A predictable layout lets both humans and CI find things without guessing. A workable convention for an R modeling project:
myproject/
renv.lock # pinned dependencies
renv/ # renv infrastructure
DESCRIPTION # project metadata, declared package deps
R/ # reusable functions (sourced, tested)
features.R
train.R
evaluate.R
data-raw/ # immutable raw inputs (never edited in place)
data/ # derived, cached datasets
models/ # serialized model artifacts + metadata
tests/
testthat/ # unit tests for data and models
testthat.R
scripts/
01-train.R # entry points that call R/ functions
02-evaluate.R
reports/
model-card.md # human-readable model documentation
.github/workflows/ # CI definitions
ci.yaml
The principle is separation of concerns: functions in R/ are pure and testable, scripts in scripts/ are thin entry points, raw data in data-raw/ is never mutated, and artifacts in models/ carry their own metadata. CI can then run tests/ without executing an expensive training job, and retraining can call the same R/ functions the tests already cover.
Tip
The payoff of keeping logic in R/ and entry points in scripts/ is that your tests and your production runs exercise the same functions. If a test passes on train_model(), you know the script that calls train_model() is running tested code, not a copy that has drifted.
118.5 Unit tests for data and models with testthat
A test, in this setting, is just a small piece of code that states what “correct” looks like and complains loudly when reality disagrees. testthat is the standard R testing framework. A test file lives under tests/testthat/, groups assertions with test_that(), and uses expectation functions (expect_equal, expect_true, expect_gt, and so on), each of which checks one claim and signals an error if it is false. For ML, tests fall into a few categories:
Data tests: schema, ranges, no leakage between train and test (disjoint keys).
Function tests: a feature transform is deterministic, handles NA, preserves row count.
Model tests: a trained model clears a metric threshold on a holdout, and does not regress below a recorded baseline.
The model tests are the ones that turn the vague claim “the model is good” into a checkable statement a machine can verify. A testthat file that gates on a threshold looks like this (shown eval=FALSE because it is meant to live in tests/testthat/, not in a rendered document):
Show code
# tests/testthat/test-model.Rlibrary(testthat)test_that("logistic model clears AUC threshold on holdout", {fit<-train_model(train_data)# from R/train.Rauc<-evaluate_auc(fit, holdout_data)# from R/evaluate.Rexpect_gt(auc, 0.80)# the promotion gate})test_that("predictions are valid probabilities", {p<-predict_prob(fit, holdout_data)expect_true(all(p>=0&p<=1))expect_equal(length(p), nrow(holdout_data))})test_that("train and holdout keys are disjoint (no leakage)", {expect_length(intersect(train_data$id, holdout_data$id), 0)})
Running the suite from the command line, which is exactly what CI does, is one call:
Show code
# From the project root, run the whole suite (used as the CI step):testthat::test_dir("tests/testthat")# In a package, the equivalent is:# devtools::test()
118.6 A runnable demo: a threshold-gating assertion
Everything so far has pointed at one object: the gate that decides whether a model is good enough to ship. It is small enough to build from scratch in base R, and seeing it in full removes any mystery about what CI is actually doing on your behalf. We implement a testthat-style assertion, assert_metric_threshold(), that trains nothing itself but takes a computed metric and a threshold, compares them, and raises an error if the metric falls short. This is the gate a CI job or a retraining script calls before promoting a model. The chunk is eval=TRUE.
Intuition
The gate has exactly two outcomes. If the metric clears the bar, it stays quiet and lets the script continue. If it does not, it stop()s, which in a script means a nonzero exit code, which is the universal signal a CI system reads as “this build failed.”
Show code
# A minimal expectation function in the spirit of testthat.# It compares a computed metric against a threshold and either# returns invisibly (pass) or stops with an informative message (fail).assert_metric_threshold<-function(metric_value, threshold,direction=c("greater", "less"),metric_name="metric"){direction<-match.arg(direction)pass<-if(direction=="greater"){metric_value>=threshold}else{metric_value<=threshold}comp<-if(direction=="greater")">="else"<="if(!pass){stop(sprintf("FAIL: %s = %.4f, required %s %.4f",metric_name, metric_value, comp, threshold), call. =FALSE)}message(sprintf("PASS: %s = %.4f (%s %.4f)",metric_name, metric_value, comp, threshold))invisible(TRUE)}# AUC via the Mann-Whitney U formulation: the probability that a# randomly chosen positive scores above a randomly chosen negative.auc_score<-function(scores, labels){pos<-scores[labels==1]neg<-scores[labels==0]if(length(pos)==0||length(neg)==0){stop("AUC undefined: holdout has only one class.", call. =FALSE)}r<-rank(c(pos, neg))# midranks handle ties(sum(r[seq_along(pos)])-length(pos)*(length(pos)+1)/2)/(length(pos)*length(neg))}
The two helpers do one job each: assert_metric_threshold() is the verdict, and auc_score() computes the metric the verdict is passed.4
Now wire it to a real model. We split data into train and holdout, fit a logistic regression, score the holdout, and run the gate.
Show code
set.seed(2024)# A synthetic binary-classification problem with signal plus noise.n<-1200x1<-rnorm(n); x2<-rnorm(n); x3<-rnorm(n)lin<--0.4+1.3*x1-1.1*x2+0.6*x3prob<-1/(1+exp(-lin))y<-rbinom(n, 1, prob)dat<-data.frame(y, x1, x2, x3, id =seq_len(n))# Reproducible 70/30 split, recorded by id so leakage is checkable.train_idx<-sample(seq_len(n), size =floor(0.7*n))train<-dat[train_idx, ]holdout<-dat[-train_idx, ]stopifnot(length(intersect(train$id, holdout$id))==0)# leakage guardfit<-glm(y~x1+x2+x3, data =train, family =binomial())phat<-predict(fit, newdata =holdout, type ="response")auc<-auc_score(phat, holdout$y)# The promotion gate: require AUC >= 0.80 on the holdout.assert_metric_threshold(auc, threshold =0.80, direction ="greater", metric_name ="holdout AUC")
The PASS message confirms the model cleared the bar: the holdout AUC came out around 0.86, comfortably above the 0.80 threshold, so the gate returned quietly and a real pipeline would proceed to promote the model.
If the model had underperformed, the call would have stopped the script with a nonzero status, which is precisely how CI learns the build failed. To see the failing branch without aborting the document, we catch the error from an impossibly strict threshold:
Here tryCatch intercepts the error so the document keeps rendering, and we print the message the gate would have raised. In a real CI run there would be no tryCatch: the error would propagate, the script would exit nonzero, and the build would turn red.
118.7 A figure: the gate as a decision boundary
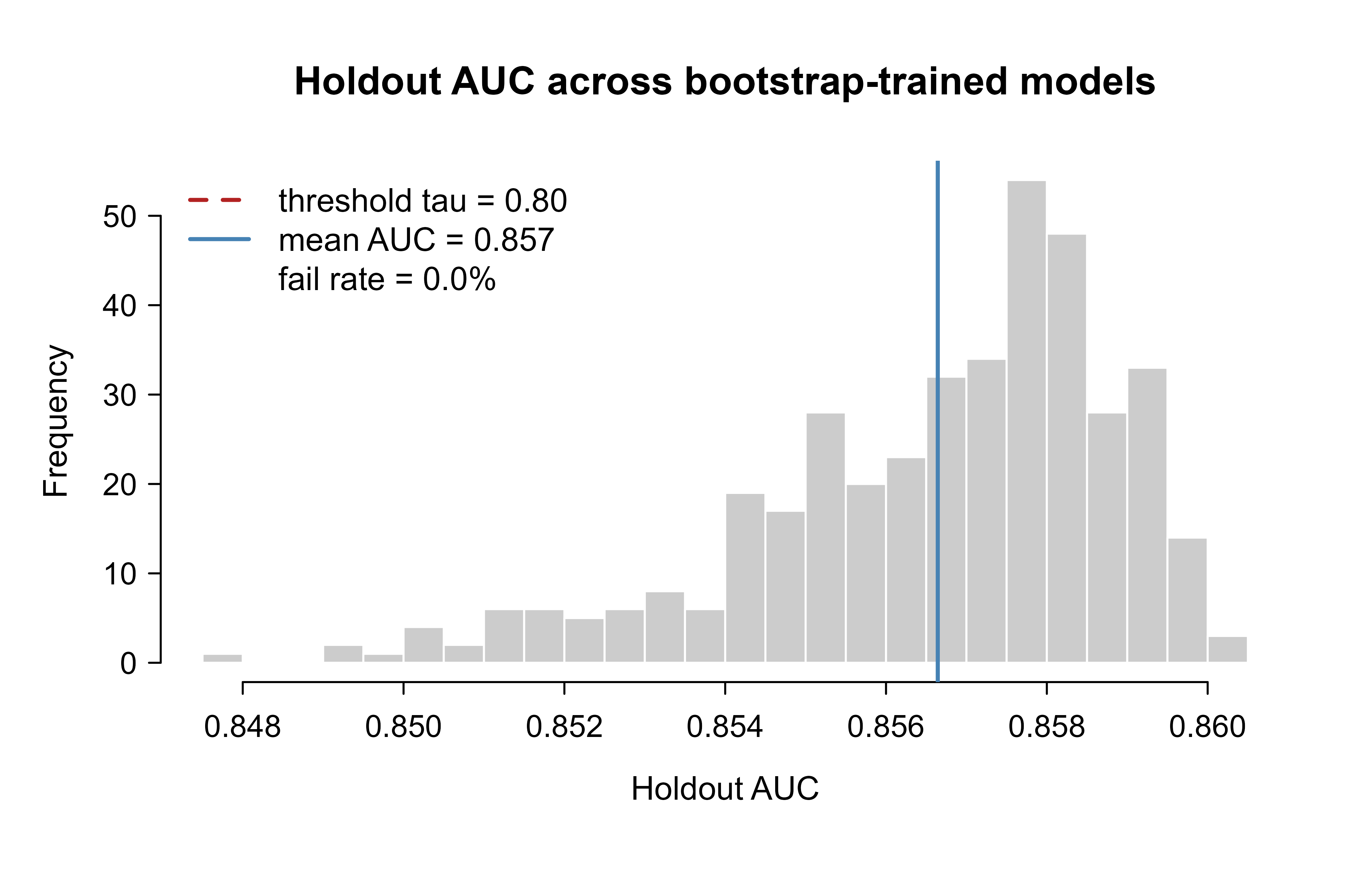
A single pass or fail tells you what happened this time, but a model retrained on slightly different data each week will not produce exactly the same metric every run. To set a sensible threshold you need to picture the whole spread of metrics the model tends to produce. The gate partitions the space of possible models into “promote” and “reject” by where their holdout metric falls relative to \(\tau\). Simulating many models trained on bootstrap resamples5 shows the distribution of the metric and where the threshold cuts it.
Figure 118.1 shows the resulting spread of holdout AUC and where the threshold cuts it.
Show code
set.seed(7)boot_auc<-replicate(400, {bi<-sample(seq_len(nrow(train)), replace =TRUE)f<-glm(y~x1+x2+x3, data =train[bi, ], family =binomial())ph<-predict(f, newdata =holdout, type ="response")auc_score(ph, holdout$y)})tau<-0.80fail_share<-mean(boot_auc<tau)hist(boot_auc, breaks =25, col ="grey80", border ="white", main ="Holdout AUC across bootstrap-trained models", xlab ="Holdout AUC")abline(v =tau, col ="firebrick", lwd =2, lty =2)abline(v =mean(boot_auc), col ="steelblue", lwd =2)legend("topleft", legend =c(sprintf("threshold tau = %.2f", tau),sprintf("mean AUC = %.3f", mean(boot_auc)),sprintf("fail rate = %.1f%%", 100*fail_share)), col =c("firebrick", "steelblue", NA), lwd =c(2, 2, NA), lty =c(2, 1, NA), bty ="n")
Figure 118.1: Distribution of holdout AUC across 400 bootstrap-trained logistic models. The dashed line is the promotion threshold; models to its left would fail the CI gate.
The fraction of the distribution to the left of \(\tau\) estimates how often a retrain would fail the gate by chance alone. In this example the whole distribution sits well to the right of 0.80, so that fraction is essentially zero and the gate is safe. If instead the threshold landed inside the bulk of the histogram, the gate would reject a healthy model on noise alone, and a flaky CI gate would result. The next section makes that failure mode precise.
118.8 A simulation: flaky gates from a tight threshold
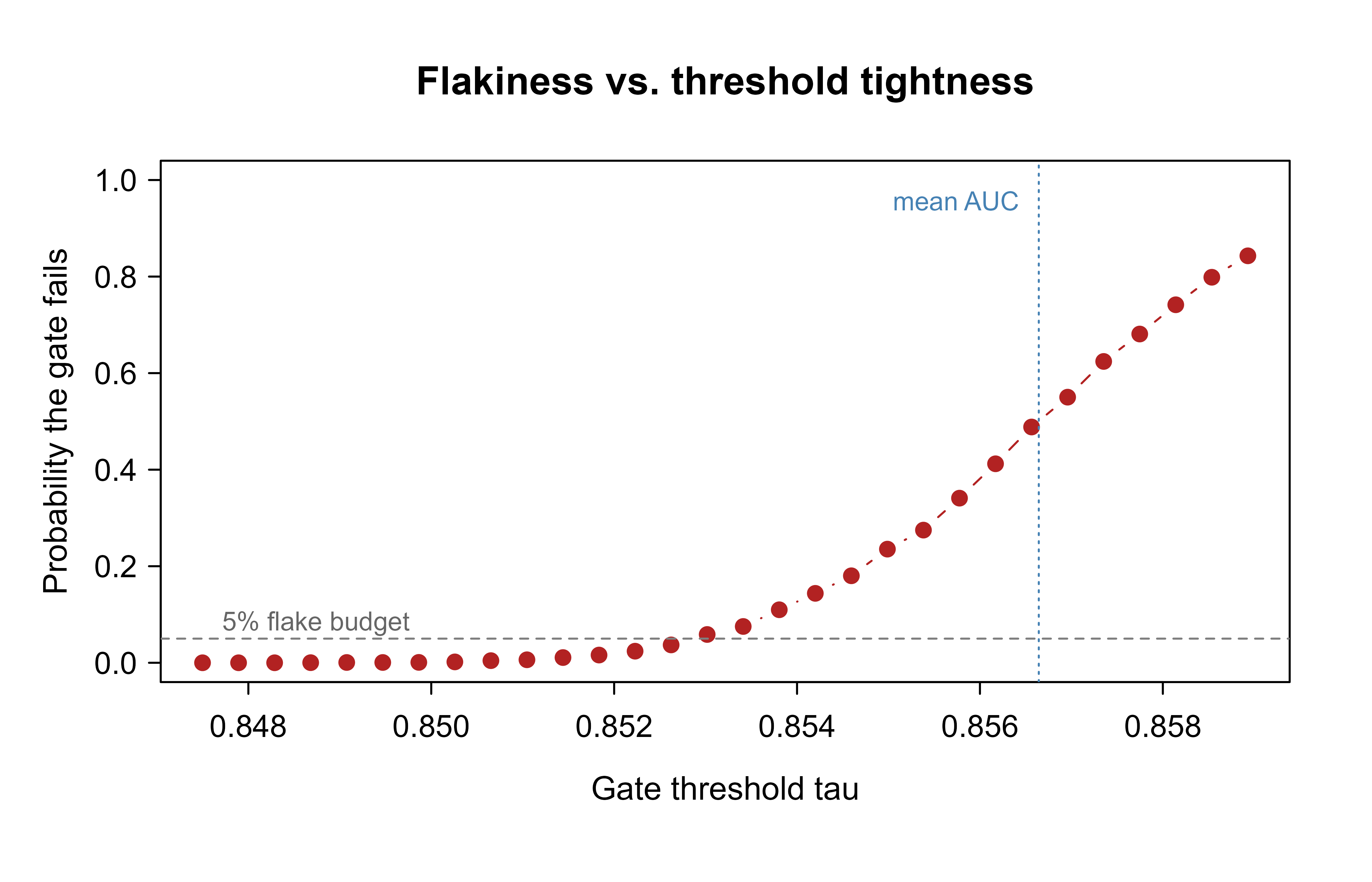
A flaky gate is one that sometimes fails for no real reason, and it is corrosive: developers learn to ignore red builds, which defeats the entire point of automation. Setting \(\tau\) too close to the model’s mean performance is the most common cause, because the holdout metric has sampling variability and will sometimes dip below the bar by chance. We quantify this by simulating retraining runs at several thresholds and measuring the false-failure rate, the probability the gate rejects a model whose true quality is acceptable. Figure 118.2 plots that rate as the threshold approaches the model’s mean performance.
Show code
set.seed(99)# Treat each retrain as drawing a holdout AUC from the bootstrap distribution.mu<-mean(boot_auc)sdv<-sd(boot_auc)thresholds<-seq(mu-4*sdv, mu+1*sdv, length.out =30)false_fail<-sapply(thresholds, function(t){draws<-rnorm(5000, mean =mu, sd =sdv)# simulated retrain outcomesmean(draws<t)# how often the gate rejects})plot(thresholds, false_fail, type ="b", pch =19, col ="firebrick", xlab ="Gate threshold tau", ylab ="Probability the gate fails", main ="Flakiness vs. threshold tightness", ylim =c(0, 1))abline(v =mu, lty =3, col ="steelblue")text(mu, 0.95, "mean AUC", pos =2, col ="steelblue", cex =0.8)abline(h =0.05, lty =2, col ="grey50")text(min(thresholds), 0.08, "5% flake budget", pos =4, col ="grey40", cex =0.8)
Figure 118.2: False-failure rate of a metric gate as the threshold approaches the model’s mean holdout AUC. A gate set just below the mean fails roughly half the time on noise alone.
The curve crosses 50% exactly at the mean, as expected for a symmetric distribution: a threshold at the mean rejects half of all otherwise-fine retrains. The lesson is that a gate is a statistical decision, not a fixed wall.
Tip
To keep the false-failure rate under a budget (say 5%), set \(\tau\) several standard deviations below the mean, or, better, report a confidence interval for the metric and gate on its lower bound rather than a point estimate. Gating on a lower bound builds the sampling noise directly into the decision.
118.9 GitHub Actions CI
So far the gate runs only when you call it. CI is what calls it for you, on every change, without your having to remember. GitHub Actions is one popular CI service; it runs a workflow (a YAML file in .github/workflows/) on triggers such as a push or a pull request.6 For an R project the job restores the pinned environment, then runs the test suite. A failing test sets a nonzero exit code, which marks the check red and can block the merge. The YAML below is eval=FALSE (it is configuration, not R) but is current and runnable.
# .github/workflows/ci.yaml -- shown for reference, not executed herename: CIon:push:branches:[main]pull_request:jobs:test:runs-on: ubuntu-latestenv:GITHUB_PAT: ${{ secrets.GITHUB_TOKEN }}steps:-uses: actions/checkout@v4-uses: r-lib/actions/setup-r@v2with:use-public-rspm:true # Restore the exact pinned environment from renv.lock.-uses: r-lib/actions/setup-renv@v2 # Run the test suite; a failing test fails the job.-name: Run testsrun: Rscript -e 'testthat::test_dir("tests/testthat", stop_on_failure = TRUE)'
Reading the steps in order: checkout fetches the code, setup-r installs R, setup-renv calls renv::restore() so CI uses the pinned versions, and the final step runs the suite with stop_on_failure = TRUE, which makes a failed expectation return a nonzero exit code. The same pattern extends to a matrix that tests several R versions or operating systems by listing them under strategy.matrix.
Warning
The setup-renv step is not optional decoration. Without it, the runner installs whatever package versions it pleases, and your carefully committed lockfile does nothing. A lockfile that is never restored gives a false sense of safety.
118.10 Automated retraining
Code is not the only thing that changes; data changes too, and a model can rot even when its code is frozen. Retraining is the same CI machinery applied on a schedule or a data trigger rather than on a code push. The workflow restores the environment, pulls fresh data, trains, runs the same threshold gate, and promotes the artifact only if the gate passes, handing it off to the serving infrastructure discussed in the model deployment chapter (Chapter 116). A scheduled GitHub Actions workflow uses a cron trigger:7
# .github/workflows/retrain.yaml -- reference onlyname: Retrainon:schedule:-cron:"0 6 * * 1" # 06:00 UTC every Mondayworkflow_dispatch:{} # also allow manual runsjobs:retrain:runs-on: ubuntu-lateststeps:-uses: actions/checkout@v4-uses: r-lib/actions/setup-r@v2-uses: r-lib/actions/setup-renv@v2-name: Train and gaterun: Rscript scripts/01-train.R && Rscript scripts/02-evaluate.R-name: Upload model if gate passedif: success()uses: actions/upload-artifact@v4with:name: modelpath: models/
The 02-evaluate.R script is where the threshold assertion from this chapter lives. Because it stop()s on failure, a model that no longer clears the bar never reaches the upload step, so a degraded model is never promoted.
Key idea
The schedule decides when to attempt a promotion; the gate decides whether to allow it. Keeping those two responsibilities separate is what prevents a calendar from shipping a bad model just because it is Monday.
The pattern that scales beyond toy projects records, on every run, the metric value, the data hash, the seed, and the package versions, so a later failure can be traced to exactly which dial of \(T(D,\theta,s,E)\) changed. That log is what turns a mysterious regression into a one-line diagnosis.
118.11 Model cards
The pipeline now produces trustworthy models automatically, but a model that nobody can describe is still hard to deploy responsibly. A model card closes that gap (see also the dedicated model card chapter, Chapter 122). Introduced by Mitchell and colleagues in 2019 (see Further reading), it is a short, structured document describing what a model is, how it was built, how it performs, and how it should and should not be used. It travels with the artifact so that whoever deploys or audits the model later does not have to reverse-engineer its provenance. A minimal card in Markdown:
Show code
# reports/model-card.md -- reference template# Model Card: Churn Classifier v1.4## ## Overview# - Task: binary classification (churn within 30 days)# - Type: penalized logistic regression (glmnet, alpha = 0.5)# - Owner: data science team; contact: ds@example.com# - Date: 2026-06-17; git commit: a1b2c3d## ## Training data# - Source: warehouse table `events.churn_features` snapshot 2026-06-15# - Rows: 240,113; positive rate: 7.2%# - Data hash (sha256): 9f2c... seed: 2024## ## Evaluation# - Holdout AUC: 0.842 (threshold for promotion: 0.80)# - Calibration: Brier score 0.061# - Slice check: AUC >= 0.78 within each region segment## ## Intended use and limits# - Use: prioritize retention outreach.# - Do not use: for credit, pricing, or any high-stakes individual decision.# - Known limits: trained on one region; not validated for new markets.## ## Environment# - R 4.4.3; package versions pinned in renv.lock (committed).
Tip
The card is most useful when it is generated, not hand-written, so that the numbers always match the run that produced the artifact. A script can fill a template from the same objects the evaluation gate already computed (the metric, the data hash, the seed, the lockfile), which keeps the card honest. A hand-edited card drifts from reality the moment someone forgets to update a number.
118.12 Comparison of practices
Having walked the chain end to end, it helps to see all the practices side by side. Table 118.1 summarizes which dial each one pins, what tool implements it, when it runs, and the specific failure it heads off.
Table 118.1: Reproducibility and CI/CD practices side by side, showing which argument of the training function each one pins, the tool that implements it, when it runs, and the failure mode it prevents.
Practice
Pins which argument
Tooling
Runs when
Failure mode it prevents
Dependency pinning
\(E\) (environment)
renv
restore at every build
“works on my machine”; silent default changes
Seed + data hash
\(s\), \(D\)
base R, digest
every train
nondeterministic fits; silent data mutation
Unit tests
code correctness
testthat
every commit (CI)
logic regressions; invalid outputs
Threshold gate
model quality
testthat / custom assertion
train and retrain
promoting an underperforming model
CI workflow
enforcement
GitHub Actions
push / pull request
merging code that breaks tests
Scheduled retraining
freshness
Actions cron
schedule / data trigger
model decay from drift
Model card
provenance
Markdown / generated
at release
undocumented, misused, or unauditable models
A mature project uses all of them, but the order of adoption matters: pin dependencies and set seeds first (cheap, high impact), add a threshold gate and a CI workflow next (turns quality into a checkable contract), then schedule retraining and generate cards once the pipeline is stable.
When to use this
You do not need the full stack to benefit. Start at the top of that adoption order and stop wherever the cost of the next layer exceeds its payoff for your project.
118.13 Practical guidance, pitfalls, and when to use it
Adopt incrementally. The biggest single win is renv plus a recorded seed; do that before anything else. The second is one testthat test that gates on a holdout metric, run in CI. You do not need the full apparatus to get most of the benefit.
Gate on a confidence bound, not a point estimate. As the simulation showed, a threshold set near the model’s mean performance produces a flaky gate. Either set \(\tau\) well below the typical metric, or compute a lower confidence bound on the metric and gate on that, so noise alone rarely fails the build.
Keep the holdout truly held out. A gate is meaningless if the holdout leaked into training, into feature engineering, or into threshold tuning. Split by a stable key, check disjointness in a test, and never tune the threshold on the same data you gate against.
Make CI fast or developers route around it. A test suite that takes an hour gets skipped. Separate quick tests (data shape, function behavior, a small-sample model fit) that run on every push from slow tests (full retraining) that run on a schedule.
Pin the environment in CI, not just locally. A lockfile that is never restored in CI gives a false sense of safety: the build still uses whatever versions the runner happens to install. The setup-renv step is what makes the pin real.
Common pitfalls. A few mistakes recur often enough to call out by name; each has a one-line fix:
Committing the project library (renv/library/) instead of just renv.lock. Commit the lockfile; ignore the library.
Forgetting renv::snapshot() after installing a package, so the lockfile drifts from the actual environment. Run renv::status() in CI to catch this.
Threshold gates with no baseline. “AUC > 0.80” is fine, but also assert “no worse than the last released model” so a regression that still clears the absolute bar is caught.
Hand-edited model cards that disagree with the artifact. Generate the card from the run.
Retraining that promotes on a schedule regardless of the gate. The schedule should trigger training; the gate, not the calendar, should decide promotion.
Treating average accuracy as sufficient. Add per-slice threshold tests so an improvement that harms a subgroup fails the build.
When the full pipeline is overkill. For a one-off analysis or a paper figure, renv plus a set seed is enough, and a couple of stopifnot() checks suffice instead of a CI workflow. The CI/CD machinery pays off when a model recurs: it is retrained, redeployed, or maintained by more than one person over time, where the same quality contract must hold on every run without a human remembering to check.
To summarize the whole chapter in one sentence: pin the environment and seed so the past is repeatable, write one assertion that gates promotion on a holdout metric, and let CI run that assertion automatically on every change and every retrain so the quality contract holds whether or not anyone is watching.
118.14 Further reading
Wickham, H. (2015). R Packages. O’Reilly. The reference for testthat, package structure, and the R/ plus tests/ layout.
Ushey, K., & Wickham, H. (2023). renv: Project Environments. Package documentation and vignettes on lockfiles and restore.
Sculley, D., Holt, G., Golovin, D., Davydov, E., Phillips, T., Ebner, D., Chaudhary, V., Young, M., Crespo, J.-F., & Dennison, D. (2015). Hidden technical debt in machine learning systems. Advances in Neural Information Processing Systems. On why ML systems rot without engineering discipline.
Mitchell, M., Wu, S., Zaldivar, A., Barnes, P., Vasserman, L., Hutchinson, B., Spitzer, E., Raji, I. D., & Gebru, T. (2019). Model cards for model reporting. Proceedings of FAT.* The origin of the model card.
Breck, E., Cai, S., Nielsen, E., Salib, M., & Sculley, D. (2017). The ML test score: a rubric for ML production readiness and technical debt reduction. IEEE Big Data. A checklist for testing and monitoring ML systems.
Humble, J., & Farley, D. (2010). Continuous Delivery. Addison-Wesley. The foundational treatment of CI/CD that the ML practices here adapt.
The terms come from software engineering. Continuous integration means every change is automatically merged into a shared build and tested; continuous delivery means every change that passes is automatically prepared for release. The “CI/CD” label bundles the two.↩︎
Here \(L\) is a loss function, \(\hat f_M\) the prediction rule of the fitted model, and \((x_i, y_i)\) the held-out test cases. The quantity \(\widehat{R}(M)\) is just an average test loss, the same kind of held-out estimate used throughout this book.↩︎
Bitwise reproducibility means the saved model object is byte-for-byte identical across runs. That is wonderful when achievable but often impossible: summing numbers in a different order on different hardware can change the last few decimal places. Statistical reproducibility asks only that the evaluation lands in the same place, which is what an automated gate actually needs.↩︎
We compute AUC (the area under the ROC curve) via its equivalent Mann-Whitney form: it equals the probability that a randomly chosen positive case is scored higher than a randomly chosen negative one. Using rank() handles tied scores correctly with midranks. Any metric would work here; AUC is just a convenient, threshold-free summary for binary classification.↩︎
A bootstrap resample draws rows from the training set with replacement to form a new training set of the same size. Refitting on many such resamples mimics the run-to-run variability you would see if the data shifted slightly, giving a cheap picture of how stable the metric is.↩︎
A pull request is a proposed change to a shared repository, reviewed before it is merged. Running tests on every pull request means broken code is caught before it ever reaches the main branch.↩︎
cron is a long-standing convention for scheduling jobs. The five fields are minute, hour, day-of-month, month, and day-of-week; 0 6 * * 1 means “at minute 0 of hour 6 on every Monday.”↩︎
Source Code
# CI/CD and Reproducibility for ML {#sec-cicd-reproducibility}```{r}#| include: falsesource("_common.R")```A model that runs on your laptop today and nowhere else tomorrow is a liability, not an asset. The gap between "it worked when I trained it" and "it works in production, again, next quarter, on a colleague's machine" is closed by two engineering practices borrowed from software: reproducibility (the same inputs and code produce the same outputs) and continuous integration / continuous delivery (CI/CD, the automatic building, testing, and shipping of changes).^[The terms come from software engineering. *Continuous integration* means every change is automatically merged into a shared build and tested; *continuous delivery* means every change that passes is automatically prepared for release. The "CI/CD" label bundles the two.] This chapter applies both to the specific shape of machine learning work in R.If you have never set up a test suite or a build pipeline, do not worry: the ideas are simpler than the acronyms suggest, and you can adopt them one piece at a time. By the end of the chapter you will know how to pin an exact computing environment so results travel between machines, write a test that refuses to ship a model unless it clears a quality bar, run that test automatically on every change, and retrain on a schedule without a human having to remember. The single runnable example is the part that matters most: a small assertion that checks a model's holdout metric and stops the build if it falls short.::: {.callout-tip title="Intuition"}Reproducibility is about making the *past* repeatable; CI/CD is about making the *future* automatic. Together they let you trust that a model you cannot personally babysit is still behaving.:::The pieces fit together as a chain. Reproducibility starts with pinning the exact package versions a project uses (`renv`) and organizing files so the pipeline is discoverable. Tests (`testthat`) state what "correct" means for data and models, including the threshold a model must clear. CI (GitHub Actions) runs those tests on every change so regressions are caught before merge. Automated retraining extends the same machinery to run on a schedule or when new data arrives. A model card records what was built and how it should be used. The runnable core of the chapter is a `testthat`-style assertion that validates a model meets a metric threshold on a holdout set, because that assertion is the gate everything else protects.## Where CI/CD and reproducibility fit in a modern ML workflowA typical project moves through stages:```set up env -> structure project -> write code + tests -> commit -> CI runs tests -> train -> evaluate vs threshold -> register model + card -> deploy -> monitor -> retrain```Reproducibility is a property that must hold at every arrow, not a step you do once. CI/CD is the automation that enforces it: instead of trusting a human to rerun the tests before merging, a machine reruns them and blocks the merge if they fail.::: {.callout-important title="Key idea"}Reproducibility is not a checkbox at the end of a project. It is an invariant that has to survive every transition in the diagram above, which is exactly why automating its enforcement pays off.:::Three observations motivate the investment.1. ML failures are often environmental, not logical. The same code gives different numbers because a dependency changed its default, a random seed was unset, or a BLAS library differs across machines. Pinning versions and seeds removes the most common source of "works on my machine."2. Models decay even when code does not. Data drifts, so a model that passed its threshold last month may fail it now. A retraining pipeline that re-runs the same evaluation gate catches decay automatically, complementing the dedicated drift surveillance covered in the model monitoring chapter (@sec-model-monitoring).3. The evaluation gate is the contract. The single most useful piece of automation is a test that refuses to promote a model unless it beats a metric threshold on held-out data. Everything else (environment pinning, CI, scheduling) exists to make that gate trustworthy and to run it without a human in the loop.In an AI/ML setting these practices also guard against a subtler problem: a change that improves average accuracy while quietly degrading a slice (a subgroup, a recent time window). Tests that assert per-slice thresholds, run in CI, turn that risk into a build failure instead of a production incident.With the motivation in place, the rest of the chapter works through the chain one link at a time, starting with the formal target that everything else serves.## Reproducibility: the formal target"Reproducible" sounds obvious until you try to pin down which things have to stay fixed. It helps, then, to state precisely what reproducibility asks for. Think of a training run as a machine with four dials; lock all four and the output should be the same every time. Let a training run be a function$$M = T(D, \theta, s, E),$$where $D$ is the training data, $\theta$ the hyperparameters and code, $s$ the random seed, $E$ the environment (R version, package versions, system libraries, hardware), and $M$ the fitted model. A run is bitwise reproducible when fixing $(D, \theta, s, E)$ always yields the same $M$. It is statistically reproducible when the resulting evaluation metric$$\widehat{R}(M) = \frac{1}{n_{\text{test}}}\sum_{i=1}^{n_{\text{test}}} L\big(y_i, \hat f_M(x_i)\big)$$is stable within a small tolerance $\epsilon$ across runs, i.e. $|\widehat{R}(M_1) - \widehat{R}(M_2)| \le \epsilon$.^[Here $L$ is a loss function, $\hat f_M$ the prediction rule of the fitted model, and $(x_i, y_i)$ the held-out test cases. The quantity $\widehat{R}(M)$ is just an average test loss, the same kind of held-out estimate used throughout this book.]Each of the four dials is a source of irreproducibility if you leave it free. The following list names each one and the cheapest way to lock it down:- $D$: pin the data with a hash or a versioned snapshot, so a silently mutated table is detected.- $\theta$: version the code (git) and record hyperparameters alongside the artifact.- $s$: set and record the seed. Many R model fits (random forests, boosting, cross-validation splits) are stochastic.- $E$: pin package versions with `renv`. This is the argument most often ignored and most often responsible for drift, because package updates change defaults and numerical behavior.The practical goal is usually statistical reproducibility, not bitwise: parallel reductions and floating-point nondeterminism make exact equality hard, but a stable metric within tolerance is enough to trust an evaluation gate.^[Bitwise reproducibility means the saved model object is byte-for-byte identical across runs. That is wonderful when achievable but often impossible: summing numbers in a different order on different hardware can change the last few decimal places. Statistical reproducibility asks only that the *evaluation* lands in the same place, which is what an automated gate actually needs.]::: {.callout-important title="Key idea"}The promotion gate is a hypothesis test in disguise. We promote $M$ only if $\widehat{R}(M)$ clears a threshold $\tau$ on a holdout the model never saw. Everything else in this chapter exists to make that test trustworthy and to run it automatically.:::## Dependency pinning with `renv`Of the four dials, the environment $E$ is the one most people forget and the one that bites hardest, because a package update can silently change a default or a numerical routine without any change to your own code. `renv` (short for "R environment") is the tool that locks it. It gives each project its own private library and records the exact version of every package in a lockfile (`renv.lock`). Restoring that lockfile on another machine reconstructs the same environment, which pins the $E$ argument above.::: {.callout-tip title="When to use this"}Reach for `renv` at the very start of any project whose results you might need to reproduce later, on another machine, or with a collaborator. It is the single highest-value reproducibility step for an R project, and it costs about three commands.:::The workflow is small. Because `renv` writes to a project library and contacts package repositories, this chunk is `eval=FALSE`, but it is the idiomatic sequence a reader runs in a real project.```{r renv-demo, eval=FALSE}# install.packages("renv") # once, into the system library# 1. Initialize: creates a project-local library and an renv.lock snapshot.renv::init()# 2. Work as usual. Install/upgrade packages into the project library.install.packages("glmnet")install.packages("yardstick")# 3. Snapshot: write the current package versions into renv.lock.# Commit renv.lock (and the renv/ infrastructure) to git.renv::snapshot()# 4. On another machine / in CI: reconstruct the exact environment.renv::restore()# 5. Audit drift between the lockfile and what is actually installed.renv::status()```The lockfile is JSON and records, per package, the version and the repository it came from. A trimmed example:```{r renv-lock, eval=FALSE}# renv.lock (excerpt) -- this is data, not code; shown for shape only# {# "R": { "Version": "4.4.3" },# "Packages": {# "glmnet": {# "Package": "glmnet",# "Version": "4.1-8",# "Source": "Repository",# "Repository": "CRAN",# "Hash": "..."# }# }# }```Two rules make `renv` pay off. Commit `renv.lock` so the environment travels with the code, and run `renv::restore()` as the first step of every CI job so the build uses pinned versions rather than whatever CRAN ships that day.::: {.callout-warning}Commit the lockfile, not the library. The actual package files live under `renv/library/` and should be left out of git (they are large and machine-specific). The lockfile is the recipe; the library is the meal, and you only need to ship the recipe.:::## Project structureA predictable layout lets both humans and CI find things without guessing. A workable convention for an R modeling project:```myproject/ renv.lock # pinned dependencies renv/ # renv infrastructure DESCRIPTION # project metadata, declared package deps R/ # reusable functions (sourced, tested) features.R train.R evaluate.R data-raw/ # immutable raw inputs (never edited in place) data/ # derived, cached datasets models/ # serialized model artifacts + metadata tests/ testthat/ # unit tests for data and models testthat.R scripts/ 01-train.R # entry points that call R/ functions 02-evaluate.R reports/ model-card.md # human-readable model documentation .github/workflows/ # CI definitions ci.yaml```The principle is separation of concerns: functions in `R/` are pure and testable, scripts in `scripts/` are thin entry points, raw data in `data-raw/` is never mutated, and artifacts in `models/` carry their own metadata. CI can then run `tests/` without executing an expensive training job, and retraining can call the same `R/` functions the tests already cover.::: {.callout-tip}The payoff of keeping logic in `R/` and entry points in `scripts/` is that your tests and your production runs exercise the *same* functions. If a test passes on `train_model()`, you know the script that calls `train_model()` is running tested code, not a copy that has drifted.:::## Unit tests for data and models with `testthat`A test, in this setting, is just a small piece of code that states what "correct" looks like and complains loudly when reality disagrees. `testthat` is the standard R testing framework. A test file lives under `tests/testthat/`, groups assertions with `test_that()`, and uses expectation functions (`expect_equal`, `expect_true`, `expect_gt`, and so on), each of which checks one claim and signals an error if it is false. For ML, tests fall into a few categories:- Data tests: schema, ranges, no leakage between train and test (disjoint keys).- Function tests: a feature transform is deterministic, handles `NA`, preserves row count.- Model tests: a trained model clears a metric threshold on a holdout, and does not regress below a recorded baseline.The model tests are the ones that turn the vague claim "the model is good" into a checkable statement a machine can verify. A `testthat` file that gates on a threshold looks like this (shown `eval=FALSE` because it is meant to live in `tests/testthat/`, not in a rendered document):```{r testthat-file, eval=FALSE}# tests/testthat/test-model.Rlibrary(testthat)test_that("logistic model clears AUC threshold on holdout", { fit <-train_model(train_data) # from R/train.R auc <-evaluate_auc(fit, holdout_data) # from R/evaluate.Rexpect_gt(auc, 0.80) # the promotion gate})test_that("predictions are valid probabilities", { p <-predict_prob(fit, holdout_data)expect_true(all(p >=0& p <=1))expect_equal(length(p), nrow(holdout_data))})test_that("train and holdout keys are disjoint (no leakage)", {expect_length(intersect(train_data$id, holdout_data$id), 0)})```Running the suite from the command line, which is exactly what CI does, is one call:```{r testthat-run, eval=FALSE}# From the project root, run the whole suite (used as the CI step):testthat::test_dir("tests/testthat")# In a package, the equivalent is:# devtools::test()```## A runnable demo: a threshold-gating assertionEverything so far has pointed at one object: the gate that decides whether a model is good enough to ship. It is small enough to build from scratch in base R, and seeing it in full removes any mystery about what CI is actually doing on your behalf. We implement a `testthat`-style assertion, `assert_metric_threshold()`, that trains nothing itself but takes a computed metric and a threshold, compares them, and raises an error if the metric falls short. This is the gate a CI job or a retraining script calls before promoting a model. The chunk is `eval=TRUE`.::: {.callout-tip title="Intuition"}The gate has exactly two outcomes. If the metric clears the bar, it stays quiet and lets the script continue. If it does not, it `stop()`s, which in a script means a nonzero exit code, which is the universal signal a CI system reads as "this build failed.":::```{r gate-engine}# A minimal expectation function in the spirit of testthat.# It compares a computed metric against a threshold and either# returns invisibly (pass) or stops with an informative message (fail).assert_metric_threshold <-function(metric_value, threshold,direction =c("greater", "less"),metric_name ="metric") { direction <-match.arg(direction) pass <-if (direction =="greater") { metric_value >= threshold } else { metric_value <= threshold } comp <-if (direction =="greater") ">="else"<="if (!pass) {stop(sprintf("FAIL: %s = %.4f, required %s %.4f", metric_name, metric_value, comp, threshold),call. =FALSE) }message(sprintf("PASS: %s = %.4f (%s %.4f)", metric_name, metric_value, comp, threshold))invisible(TRUE)}# AUC via the Mann-Whitney U formulation: the probability that a# randomly chosen positive scores above a randomly chosen negative.auc_score <-function(scores, labels) { pos <- scores[labels ==1] neg <- scores[labels ==0]if (length(pos) ==0||length(neg) ==0) {stop("AUC undefined: holdout has only one class.", call. =FALSE) } r <-rank(c(pos, neg)) # midranks handle ties (sum(r[seq_along(pos)]) -length(pos) * (length(pos) +1) /2) / (length(pos) *length(neg))}```The two helpers do one job each: `assert_metric_threshold()` is the verdict, and `auc_score()` computes the metric the verdict is passed.^[We compute AUC (the area under the ROC curve) via its equivalent Mann-Whitney form: it equals the probability that a randomly chosen positive case is scored higher than a randomly chosen negative one. Using `rank()` handles tied scores correctly with midranks. Any metric would work here; AUC is just a convenient, threshold-free summary for binary classification.]Now wire it to a real model. We split data into train and holdout, fit a logistic regression, score the holdout, and run the gate.```{r gate-demo}set.seed(2024)# A synthetic binary-classification problem with signal plus noise.n <-1200x1 <-rnorm(n); x2 <-rnorm(n); x3 <-rnorm(n)lin <--0.4+1.3* x1 -1.1* x2 +0.6* x3prob <-1/ (1+exp(-lin))y <-rbinom(n, 1, prob)dat <-data.frame(y, x1, x2, x3, id =seq_len(n))# Reproducible 70/30 split, recorded by id so leakage is checkable.train_idx <-sample(seq_len(n), size =floor(0.7* n))train <- dat[train_idx, ]holdout <- dat[-train_idx, ]stopifnot(length(intersect(train$id, holdout$id)) ==0) # leakage guardfit <-glm(y ~ x1 + x2 + x3, data = train, family =binomial())phat <-predict(fit, newdata = holdout, type ="response")auc <-auc_score(phat, holdout$y)# The promotion gate: require AUC >= 0.80 on the holdout.assert_metric_threshold(auc, threshold =0.80,direction ="greater", metric_name ="holdout AUC")```The `PASS` message confirms the model cleared the bar: the holdout AUC came out around 0.86, comfortably above the 0.80 threshold, so the gate returned quietly and a real pipeline would proceed to promote the model.If the model had underperformed, the call would have stopped the script with a nonzero status, which is precisely how CI learns the build failed. To see the failing branch without aborting the document, we catch the error from an impossibly strict threshold:```{r gate-fail}result <-tryCatch(assert_metric_threshold(auc, threshold =0.999,direction ="greater", metric_name ="holdout AUC"),error =function(e) conditionMessage(e))result```Here `tryCatch` intercepts the error so the document keeps rendering, and we print the message the gate would have raised. In a real CI run there would be no `tryCatch`: the error would propagate, the script would exit nonzero, and the build would turn red.## A figure: the gate as a decision boundaryA single pass or fail tells you what happened *this* time, but a model retrained on slightly different data each week will not produce exactly the same metric every run. To set a sensible threshold you need to picture the whole spread of metrics the model tends to produce. The gate partitions the space of possible models into "promote" and "reject" by where their holdout metric falls relative to $\tau$. Simulating many models trained on bootstrap resamples^[A *bootstrap resample* draws rows from the training set with replacement to form a new training set of the same size. Refitting on many such resamples mimics the run-to-run variability you would see if the data shifted slightly, giving a cheap picture of how stable the metric is.] shows the distribution of the metric and where the threshold cuts it.@fig-cicd-reproducibility-gate-distribution shows the resulting spread of holdout AUC and where the threshold cuts it.```{r fig-cicd-reproducibility-gate-distribution, fig.cap="Distribution of holdout AUC across 400 bootstrap-trained logistic models. The dashed line is the promotion threshold; models to its left would fail the CI gate.", fig.width=7, fig.height=4.5}set.seed(7)boot_auc <-replicate(400, { bi <-sample(seq_len(nrow(train)), replace =TRUE) f <-glm(y ~ x1 + x2 + x3, data = train[bi, ], family =binomial()) ph <-predict(f, newdata = holdout, type ="response")auc_score(ph, holdout$y)})tau <-0.80fail_share <-mean(boot_auc < tau)hist(boot_auc, breaks =25, col ="grey80", border ="white",main ="Holdout AUC across bootstrap-trained models",xlab ="Holdout AUC")abline(v = tau, col ="firebrick", lwd =2, lty =2)abline(v =mean(boot_auc), col ="steelblue", lwd =2)legend("topleft",legend =c(sprintf("threshold tau = %.2f", tau),sprintf("mean AUC = %.3f", mean(boot_auc)),sprintf("fail rate = %.1f%%", 100* fail_share)),col =c("firebrick", "steelblue", NA),lwd =c(2, 2, NA), lty =c(2, 1, NA), bty ="n")```The fraction of the distribution to the left of $\tau$ estimates how often a retrain would fail the gate by chance alone. In this example the whole distribution sits well to the right of 0.80, so that fraction is essentially zero and the gate is safe. If instead the threshold landed inside the bulk of the histogram, the gate would reject a healthy model on noise alone, and a flaky CI gate would result. The next section makes that failure mode precise.## A simulation: flaky gates from a tight thresholdA *flaky* gate is one that sometimes fails for no real reason, and it is corrosive: developers learn to ignore red builds, which defeats the entire point of automation. Setting $\tau$ too close to the model's mean performance is the most common cause, because the holdout metric has sampling variability and will sometimes dip below the bar by chance. We quantify this by simulating retraining runs at several thresholds and measuring the false-failure rate, the probability the gate rejects a model whose true quality is acceptable. @fig-cicd-reproducibility-flaky-gate plots that rate as the threshold approaches the model's mean performance.```{r fig-cicd-reproducibility-flaky-gate, fig.cap="False-failure rate of a metric gate as the threshold approaches the model's mean holdout AUC. A gate set just below the mean fails roughly half the time on noise alone.", fig.width=7, fig.height=4.5}set.seed(99)# Treat each retrain as drawing a holdout AUC from the bootstrap distribution.mu <-mean(boot_auc)sdv <-sd(boot_auc)thresholds <-seq(mu -4* sdv, mu +1* sdv, length.out =30)false_fail <-sapply(thresholds, function(t) { draws <-rnorm(5000, mean = mu, sd = sdv) # simulated retrain outcomesmean(draws < t) # how often the gate rejects})plot(thresholds, false_fail, type ="b", pch =19, col ="firebrick",xlab ="Gate threshold tau",ylab ="Probability the gate fails",main ="Flakiness vs. threshold tightness",ylim =c(0, 1))abline(v = mu, lty =3, col ="steelblue")text(mu, 0.95, "mean AUC", pos =2, col ="steelblue", cex =0.8)abline(h =0.05, lty =2, col ="grey50")text(min(thresholds), 0.08, "5% flake budget", pos =4, col ="grey40", cex =0.8)```The curve crosses 50% exactly at the mean, as expected for a symmetric distribution: a threshold at the mean rejects half of all otherwise-fine retrains. The lesson is that a gate is a statistical decision, not a fixed wall.::: {.callout-tip}To keep the false-failure rate under a budget (say 5%), set $\tau$ several standard deviations below the mean, or, better, report a confidence interval for the metric and gate on its lower bound rather than a point estimate. Gating on a lower bound builds the sampling noise directly into the decision.:::## GitHub Actions CISo far the gate runs only when you call it. CI is what calls it for you, on every change, without your having to remember. GitHub Actions is one popular CI service; it runs a *workflow* (a YAML file in `.github/workflows/`) on triggers such as a push or a pull request.^[A *pull request* is a proposed change to a shared repository, reviewed before it is merged. Running tests on every pull request means broken code is caught before it ever reaches the main branch.] For an R project the job restores the pinned environment, then runs the test suite. A failing test sets a nonzero exit code, which marks the check red and can block the merge. The YAML below is `eval=FALSE` (it is configuration, not R) but is current and runnable.```yaml# .github/workflows/ci.yaml -- shown for reference, not executed herename: CIon:push:branches:[main]pull_request:jobs:test:runs-on: ubuntu-latestenv:GITHUB_PAT: ${{ secrets.GITHUB_TOKEN }}steps:-uses: actions/checkout@v4-uses: r-lib/actions/setup-r@v2with:use-public-rspm:true # Restore the exact pinned environment from renv.lock.-uses: r-lib/actions/setup-renv@v2 # Run the test suite; a failing test fails the job.-name: Run testsrun: Rscript -e 'testthat::test_dir("tests/testthat", stop_on_failure = TRUE)'```Reading the steps in order: `checkout` fetches the code, `setup-r` installs R, `setup-renv` calls `renv::restore()` so CI uses the pinned versions, and the final step runs the suite with `stop_on_failure = TRUE`, which makes a failed expectation return a nonzero exit code. The same pattern extends to a matrix that tests several R versions or operating systems by listing them under `strategy.matrix`.::: {.callout-warning}The `setup-renv` step is not optional decoration. Without it, the runner installs whatever package versions it pleases, and your carefully committed lockfile does nothing. A lockfile that is never restored gives a false sense of safety.:::## Automated retrainingCode is not the only thing that changes; data changes too, and a model can rot even when its code is frozen. Retraining is the same CI machinery applied on a schedule or a data trigger rather than on a code push. The workflow restores the environment, pulls fresh data, trains, runs the same threshold gate, and promotes the artifact only if the gate passes, handing it off to the serving infrastructure discussed in the model deployment chapter (@sec-model-deployment). A scheduled GitHub Actions workflow uses a `cron` trigger:^[`cron` is a long-standing convention for scheduling jobs. The five fields are minute, hour, day-of-month, month, and day-of-week; `0 6 * * 1` means "at minute 0 of hour 6 on every Monday."]```yaml# .github/workflows/retrain.yaml -- reference onlyname: Retrainon:schedule:-cron:"0 6 * * 1" # 06:00 UTC every Mondayworkflow_dispatch:{} # also allow manual runsjobs:retrain:runs-on: ubuntu-lateststeps:-uses: actions/checkout@v4-uses: r-lib/actions/setup-r@v2-uses: r-lib/actions/setup-renv@v2-name: Train and gaterun: Rscript scripts/01-train.R && Rscript scripts/02-evaluate.R-name: Upload model if gate passedif: success()uses: actions/upload-artifact@v4with:name: modelpath: models/```The `02-evaluate.R` script is where the threshold assertion from this chapter lives. Because it `stop()`s on failure, a model that no longer clears the bar never reaches the upload step, so a degraded model is never promoted.::: {.callout-important title="Key idea"}The schedule decides *when* to attempt a promotion; the gate decides *whether* to allow it. Keeping those two responsibilities separate is what prevents a calendar from shipping a bad model just because it is Monday.:::The pattern that scales beyond toy projects records, on every run, the metric value, the data hash, the seed, and the package versions, so a later failure can be traced to exactly which dial of $T(D,\theta,s,E)$ changed. That log is what turns a mysterious regression into a one-line diagnosis.## Model cardsThe pipeline now produces trustworthy models automatically, but a model that nobody can describe is still hard to deploy responsibly. A model card closes that gap (see also the dedicated model card chapter, @sec-model-card). Introduced by Mitchell and colleagues in 2019 (see Further reading), it is a short, structured document describing what a model is, how it was built, how it performs, and how it should and should not be used. It travels with the artifact so that whoever deploys or audits the model later does not have to reverse-engineer its provenance. A minimal card in Markdown:```{r model-card, eval=FALSE}# reports/model-card.md -- reference template# Model Card: Churn Classifier v1.4## ## Overview# - Task: binary classification (churn within 30 days)# - Type: penalized logistic regression (glmnet, alpha = 0.5)# - Owner: data science team; contact: ds@example.com# - Date: 2026-06-17; git commit: a1b2c3d## ## Training data# - Source: warehouse table `events.churn_features` snapshot 2026-06-15# - Rows: 240,113; positive rate: 7.2%# - Data hash (sha256): 9f2c... seed: 2024## ## Evaluation# - Holdout AUC: 0.842 (threshold for promotion: 0.80)# - Calibration: Brier score 0.061# - Slice check: AUC >= 0.78 within each region segment## ## Intended use and limits# - Use: prioritize retention outreach.# - Do not use: for credit, pricing, or any high-stakes individual decision.# - Known limits: trained on one region; not validated for new markets.## ## Environment# - R 4.4.3; package versions pinned in renv.lock (committed).```::: {.callout-tip}The card is most useful when it is generated, not hand-written, so that the numbers always match the run that produced the artifact. A script can fill a template from the same objects the evaluation gate already computed (the metric, the data hash, the seed, the lockfile), which keeps the card honest. A hand-edited card drifts from reality the moment someone forgets to update a number.:::## Comparison of practicesHaving walked the chain end to end, it helps to see all the practices side by side. @tbl-cicd-reproducibility-practices summarizes which dial each one pins, what tool implements it, when it runs, and the specific failure it heads off.| Practice | Pins which argument | Tooling | Runs when | Failure mode it prevents ||---|---|---|---|---|| Dependency pinning | $E$ (environment) |`renv`| restore at every build | "works on my machine"; silent default changes || Seed + data hash | $s$, $D$ | base R, `digest`| every train | nondeterministic fits; silent data mutation || Unit tests | code correctness |`testthat`| every commit (CI) | logic regressions; invalid outputs || Threshold gate | model quality |`testthat` / custom assertion | train and retrain | promoting an underperforming model || CI workflow | enforcement | GitHub Actions | push / pull request | merging code that breaks tests || Scheduled retraining | freshness | Actions `cron`| schedule / data trigger | model decay from drift || Model card | provenance | Markdown / generated | at release | undocumented, misused, or unauditable models |: Reproducibility and CI/CD practices side by side, showing which argument of the training function each one pins, the tool that implements it, when it runs, and the failure mode it prevents. {#tbl-cicd-reproducibility-practices}A mature project uses all of them, but the order of adoption matters: pin dependencies and set seeds first (cheap, high impact), add a threshold gate and a CI workflow next (turns quality into a checkable contract), then schedule retraining and generate cards once the pipeline is stable.::: {.callout-tip title="When to use this"}You do not need the full stack to benefit. Start at the top of that adoption order and stop wherever the cost of the next layer exceeds its payoff for your project.:::## Practical guidance, pitfalls, and when to use itAdopt incrementally. The biggest single win is `renv` plus a recorded seed; do that before anything else. The second is one `testthat` test that gates on a holdout metric, run in CI. You do not need the full apparatus to get most of the benefit.Gate on a confidence bound, not a point estimate. As the simulation showed, a threshold set near the model's mean performance produces a flaky gate. Either set $\tau$ well below the typical metric, or compute a lower confidence bound on the metric and gate on that, so noise alone rarely fails the build.Keep the holdout truly held out. A gate is meaningless if the holdout leaked into training, into feature engineering, or into threshold tuning. Split by a stable key, check disjointness in a test, and never tune the threshold on the same data you gate against.Make CI fast or developers route around it. A test suite that takes an hour gets skipped. Separate quick tests (data shape, function behavior, a small-sample model fit) that run on every push from slow tests (full retraining) that run on a schedule.Pin the environment in CI, not just locally. A lockfile that is never restored in CI gives a false sense of safety: the build still uses whatever versions the runner happens to install. The `setup-renv` step is what makes the pin real.Common pitfalls. A few mistakes recur often enough to call out by name; each has a one-line fix:- Committing the project library (`renv/library/`) instead of just `renv.lock`. Commit the lockfile; ignore the library.- Forgetting `renv::snapshot()` after installing a package, so the lockfile drifts from the actual environment. Run `renv::status()` in CI to catch this.- Threshold gates with no baseline. "AUC > 0.80" is fine, but also assert "no worse than the last released model" so a regression that still clears the absolute bar is caught.- Hand-edited model cards that disagree with the artifact. Generate the card from the run.- Retraining that promotes on a schedule regardless of the gate. The schedule should trigger training; the gate, not the calendar, should decide promotion.- Treating average accuracy as sufficient. Add per-slice threshold tests so an improvement that harms a subgroup fails the build.When the full pipeline is overkill. For a one-off analysis or a paper figure, `renv` plus a set seed is enough, and a couple of `stopifnot()` checks suffice instead of a CI workflow. The CI/CD machinery pays off when a model recurs: it is retrained, redeployed, or maintained by more than one person over time, where the same quality contract must hold on every run without a human remembering to check.To summarize the whole chapter in one sentence: pin the environment and seed so the past is repeatable, write one assertion that gates promotion on a holdout metric, and let CI run that assertion automatically on every change and every retrain so the quality contract holds whether or not anyone is watching.## Further reading- Wickham, H. (2015). *R Packages.* O'Reilly. The reference for `testthat`, package structure, and the `R/` plus `tests/` layout.- Ushey, K., & Wickham, H. (2023). *renv: Project Environments.* Package documentation and vignettes on lockfiles and restore.- Sculley, D., Holt, G., Golovin, D., Davydov, E., Phillips, T., Ebner, D., Chaudhary, V., Young, M., Crespo, J.-F., & Dennison, D. (2015). Hidden technical debt in machine learning systems. *Advances in Neural Information Processing Systems.* On why ML systems rot without engineering discipline.- Mitchell, M., Wu, S., Zaldivar, A., Barnes, P., Vasserman, L., Hutchinson, B., Spitzer, E., Raji, I. D., & Gebru, T. (2019). Model cards for model reporting. *Proceedings of FAT*.* The origin of the model card.- Breck, E., Cai, S., Nielsen, E., Salib, M., & Sculley, D. (2017). The ML test score: a rubric for ML production readiness and technical debt reduction. *IEEE Big Data.* A checklist for testing and monitoring ML systems.- Humble, J., & Farley, D. (2010). *Continuous Delivery.* Addison-Wesley. The foundational treatment of CI/CD that the ML practices here adapt.